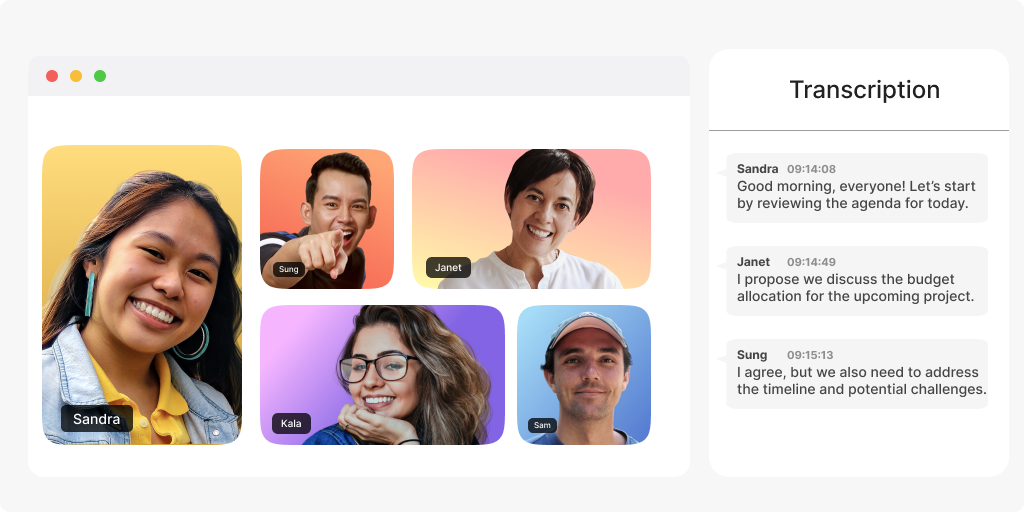
In this blog post, I'll walk you through a method of retrieving data from your meeting for real-time processing without relying on your customers' devices.
Let's consider a 2-person SFU-based meeting where each participant's device has to manage its own audio and video, convert it to the right formats, and then transmit the feeds while also receiving the audio and video from the second participant and playing it. During this process, each device manages the camera and microphones, generates streams of data, compresses and transcodes data, then decompresses and renders the audio and video frames.
For new or highly performant devices, this may only take up a small percentage of the processing power. However, for an Android phone from 6 years ago, this basic use case may require 50% or more of its processing power. Each additional step we add to this pipeline will require additional processing power and could start to impact the ability of the device to transmit and receive the audio and video.
To continue down this path, imagine adding captions to the meeting (also known as transcription). It involves tapping into both users' audio feeds, passing the data to a library that can convert the audio stream into text, and then transmitting the text for both users to see.
This path allows you to achieve your goal but think about the downsides. Each device has to add another layer of processing, then sending and receiving data to be able to display the captions. If we expand this into a 3, 5, or 10-person meeting, this extra processing starts to add up and can limit your ability to access and act based on the real-time data.
A solution is to introduce a single collection user to each of your meetings. Don’t worry, this is just a name to represent a connection to a meeting that does not have its own representation in your user interface. The purpose of this connection is to receive the audio and video feeds from all other participants and perform your custom actions on that data. Since this is a connection to your meeting, you can optionally have it transmit data back to the users.
In our scenario, this collection user would subscribe to the audio feeds of both users in the media, pass the streams through our transformer library, and then transmit the text output to both users through the default chat channel.
Thanks to LiveSwitch's flexibility, this collection user can be created using a server-side application on cloud hardware with plenty of processing power. Based on the intensity of your use case, you can adjust the cloud servers you use to host your collection users.
Now, each device only needs to transmit its audio and video, which it would have already done, and listen to the chat channel and display the text on the screen. This substantially reduces the load on the customer devices and can be scaled to have multiple forms of processing down in a single meeting. For instance, one collection user could focus on transcription, another could analyze the number of people in each video feed, and yet another could scan audio for multiple voices. The sky's the limit!
Check out this F# sample application to see the collection user in action. In this example, we listen to the audio stream of the remote media, pass them through a transcription library, Vosk, and output the transcription into the chat data channel for all the users to see.
Need assistance in architecting the perfect WebRTC application? Let our team help out! Get in touch with us today!
/LiveSwitch.io%20(v2)%20-%20Solutions/LiveSwitch.io%20(v2)%20-%20By%20Industry/LiveSwitch.io%20(v2)%20-%20iGaming/ls-industry-igaming.svg)
/LiveSwitch.io%20(v2)%20-%20Solutions/LiveSwitch.io%20(v2)%20-%20By%20Use%20Case/LiveSwitch.io%20(v2)%20-%20Financial/ls-use-cases-financial-services-icon1.svg)
/LiveSwitch.io%20(v2)%20-%20Solutions/LiveSwitch.io%20(v2)%20-%20By%20Industry/LiveSwitch.io%20(v2)%20-%20Industry%20Section%20Page/ls-industry-virtual-classrooms.svg)


/LiveSwitch.io%20(v2)%20-%20Global%20Elements/Resources%20Icons/ls-resources-datasheets-iconm.svg)
/LiveSwitch.io%20(v2)%20-%20Global%20Elements/Developer%20Icons/ls-developers-get-started.svg)
/LiveSwitch.io%20(v2)%20-%20Global%20Elements/Developer%20Icons/ls-developers-cloud-guides.svg)
/LiveSwitch.io%20(v2)%20-%20Global%20Elements/Developer%20Icons/ls-developers-rest-api-references.svg)
/LiveSwitch.io%20(v2)%20-%20Global%20Elements/Developer%20Icons/ls-developer-support-faq.svg)
/LiveSwitch.io%20(v2)%20-%20Global%20Elements/Developer%20Icons/ls-developers-release-notes.svg)
/LiveSwitch.io%20(v2)%20-%20Global%20Elements/Developer%20Icons/ls-developers-cloud-console-login.svg)
/LiveSwitch.io%20(v2)%20-%20Global%20Elements/Developer%20Icons/ls-developers-install-using-docker.svg)
/LiveSwitch.io%20(v2)%20-%20Developer%20Center/ls-developer-center-cta-card.svg)